










Chatbots like ChatGPT, Claude.ai, and phind can be quite helpful, but you might not always want your questions or sensitive data handled by an external application. That’s especially true on platforms where your interactions may be reviewed by humans and otherwise used to help train future models.
One solution is to download a large language model (LLM) and run it on your own machine. That way, an outside company never has access to your data. This is also a quick option to try some new specialty models such as Meta’s recently announced Code Llama family of models, which are tuned for coding, and SeamlessM4T, aimed at text-to-speech and language translations.
Running your own LLM might sound complicated, but with the right tools, it’s surprisingly easy. And the hardware requirements for many models aren’t crazy. I’ve tested the options presented in this article on two systems: a Dell PC with an Intel i9 processor, 64GB of RAM, and a Nvidia GeForce 12GB GPU (which likely wasn’t engaged running much of this software), and on a Mac with an M1 chip but just 16GB of RAM.
Be advised that it may take a little research to find a model that performs reasonably well for your task and runs on your desktop hardware. And, few may be as good as what you’re used to with a tool like ChatGPT (especially with GPT-4) or Claude.ai. Simon Willison, creator of the command-line tool LLM, argued in a presentation last month that running a local model could be worthwhile even if its responses are wrong:
[Some of] the ones that run on your laptop will hallucinate like wild— which I think is actually a great reason to run them, because running the weak models on your laptop is a much faster way of understanding how these things work and what their limitations are.
It’s also worth noting that open source models are likely to keep improving, and some industry watchers expect the gap between them and commercial leaders to narrow.
Table of Contents
Run a local chatbot with GPT4All
If you want a chatbot that runs locally and won’t send data elsewhere, GPT4All offers a desktop client for download that’s quite easy to set up. It includes options for models that run on your own system, and there are versions for Windows, macOS, and Ubuntu.
When you open the GPT4All desktop application for the first time, you’ll see options to download around 10 (as of this writing) models that can run locally. Among them is Llama-2-7B chat, a model from Meta AI. You can also set up OpenAI’s GPT-3.5 and GPT-4 (if you have access) for non-local use if you have an API key.
The model-download portion of the GPT4All interface was a bit confusing at first. After I downloaded several models, I still saw the option to download them all. That suggested the downloads didn’t work. However, when I checked the download path, the models were there.
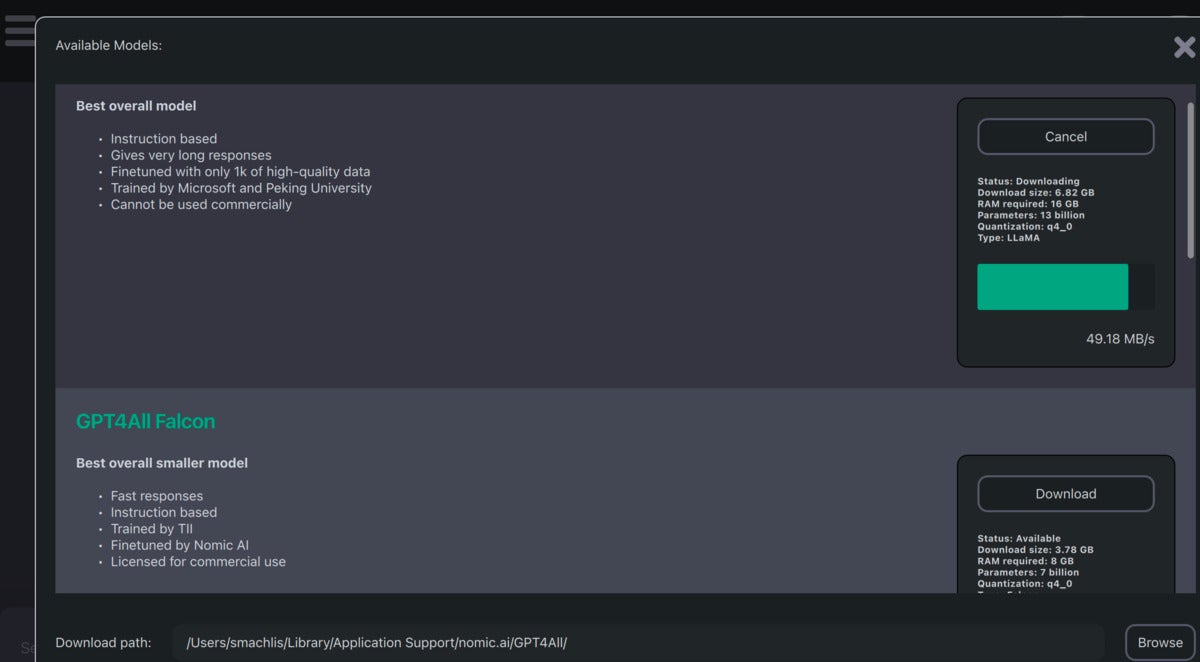 Screenshot by Sharon Machlis for IDG
Screenshot by Sharon Machlis for IDGA portion of the model download interface in GPT4All. Once I opened the usage portion of the application, my downloaded models automatically appeared.
Once the models are set up, the chatbot interface itself is clean and easy to use. Handy options include copying a chat to a clipboard and generating a response.
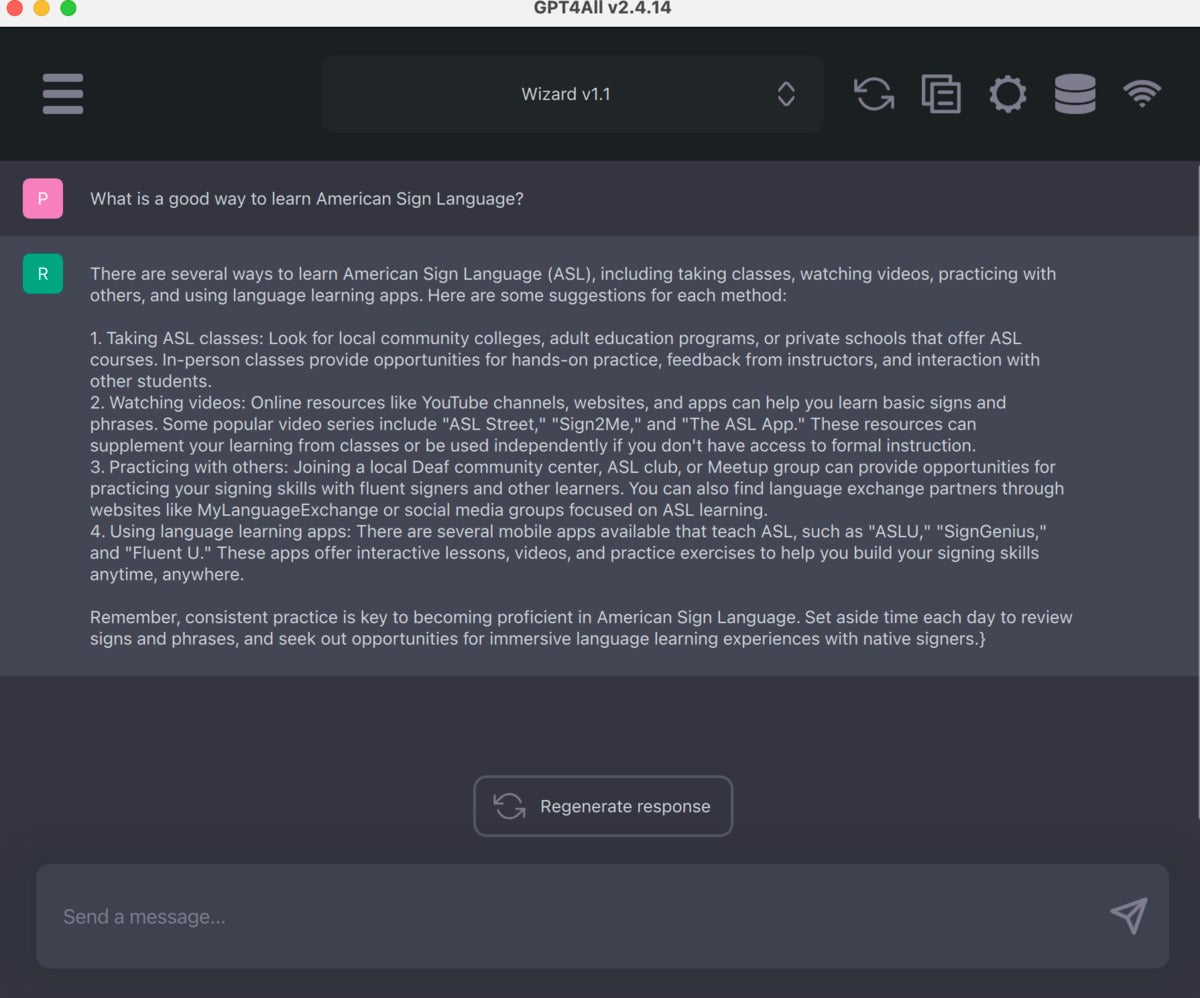 Screenshot by Sharon Machlis for IDG
Screenshot by Sharon Machlis for IDGThe GPT4All chat interface is clean and easy to use.
There’s also a new beta LocalDocs plugin that lets you “chat” with your own documents locally. You can enable it in the Settings > Plugins tab, where you’ll see a “LocalDocs Plugin (BETA) Settings” header and an option to create a collection at a specific folder path.
The plugin is a work in progress, and documentation warns that the LLM may still “hallucinate” (make things up) even when it has access to your added expert information. Nevertheless, it’s an interesting feature that’s likely to improve as open source models become more capable.
In addition to the chatbot application, GPT4All also has bindings for Python, Node, and a command-line interface (CLI). There’s also a server mode that lets you interact with the local LLM through an HTTP API structured very much like OpenAI’s. The goal is to let you swap in a local LLM for OpenAI’s by changing a couple of lines of code.
LLMs on the command line
LLM by Simon Willison is one of the easier ways I’ve seen to download and use open source LLMs locally on your own machine. While you do need Python installed to run it, you shouldn’t need to touch any Python code. If you’re on a Mac and use Homebrew, just install with
brew install llm
If you’re on a Windows machine, use your favorite way of installing Python libraries, such as
pip install llm
LLM defaults to using OpenAI models, but you can use plugins to run other models locally. For example, if you install the gpt4all plugin, you’ll have access to additional local models from GPT4All. There are also plugins for llama, the MLC project, and MPT-30B, as well as additional remote models.
Install a plugin on the command line with llm install model-name:
llm install llm-gpt4all
You can see all available models—remote and the ones you’ve installed, including brief info about each one, with the command: llm models list.
 Screenshot by Sharon Machlis for IDG
Screenshot by Sharon Machlis for IDGThe display when you ask LLM to list available models.
To send a query to a local LLM, use the syntax:
llm -m the-model-name "Your query"
I then asked it a ChatGPT-like question without issuing a separate command to download the model:
llm -m ggml-model-gpt4all-falcon-q4_0 "Tell me a joke about computer programming"
This is one thing that makes the LLM user experience so elegant: If the GPT4All model doesn’t exist on your local system, the LLM tool automatically downloads it for you before running your query. You’ll see a progress bar in the terminal as the model is downloading.
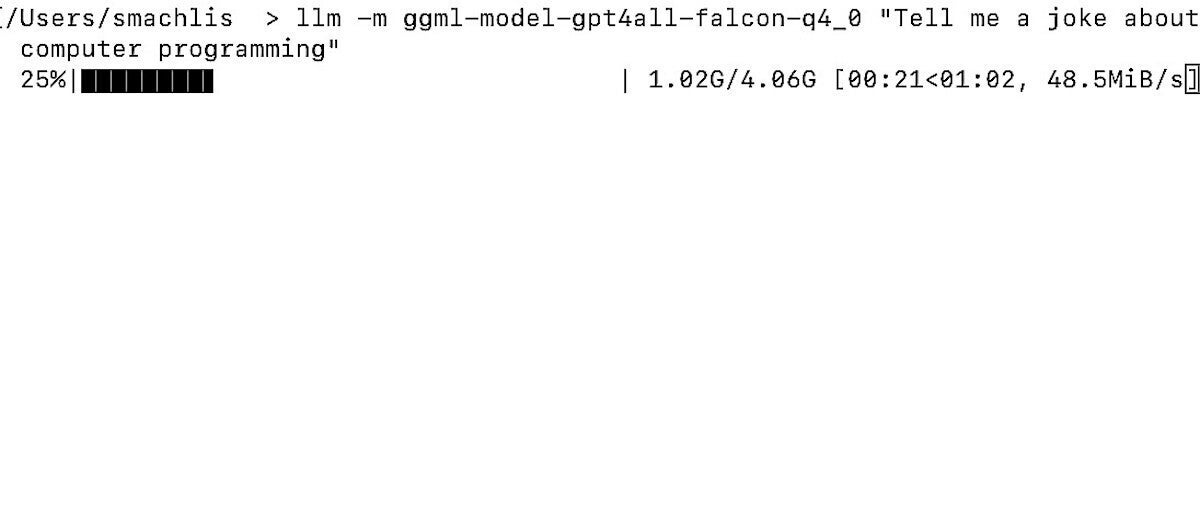 Screenshot by Sharon Machlis for IDG
Screenshot by Sharon Machlis for IDGLLM automatically downloaded the model I used in a query.
The joke itself wasn’t outstanding—”Why did the programmer turn off his computer? Because he wanted to see if it was still working!”—but the query did, in fact, work. And if results are disappointing, that’s because of model performance or inadequate user prompting, not the LLM tool.
You can also set aliases for models within LLM, so that you can refer to them by shorter names:
llm aliases set falcon ggml-model-gpt4all-falcon-q4_0
To see all your available aliases, enter: llm aliases.
The LLM plugin for Meta’s Llama models requires a bit more setup than GPT4All does. Read the details on the LLM plugin’s GitHub repo. Note that the general-purpose llama-2-7b-chat did manage to run on my work Mac with the M1 Pro chip and just 16GB of RAM. It ran rather slowly compared with the GPT4All models optimized for smaller machines without GPUs, and performed better on my more robust home PC.
LLM has other features, such as an argument flag that lets you continue from a prior chat and the ability to use it within a Python script. And in early September, the app gained tools for generating text embeddings, numerical representations of what the text means that can be used to search for related documents. You can see more on the LLM website. Willison, co-creator of the popular Python Django framework, hopes that others in the community will contribute more plugins to the LLM ecosystem.
Llama models on your desktop: Ollama
Ollama is an even easier way to download and run models than LLM. However, the project was limited to macOS and Linux until mid-February, when a preview version for Windows finally became available. I tested the Mac version.
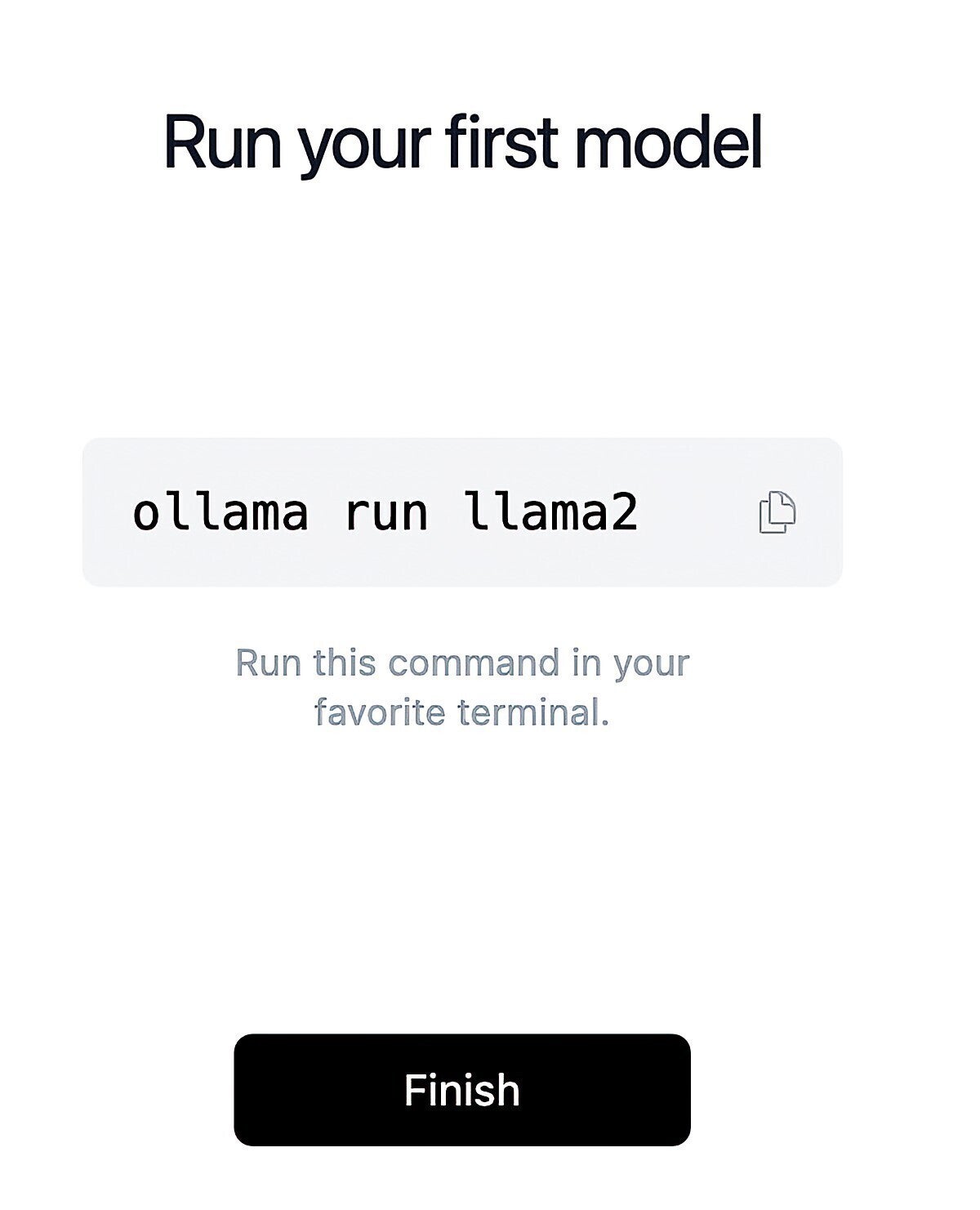 Screenshot by Sharon Machlis for IDG
Screenshot by Sharon Machlis for IDGSetting up Ollama is extremely simple.
Installation is an elegant experience via point-and-click. And although Ollama is a command-line tool, there’s just one command with the syntax ollama run model-name. As with LLM, if the model isn’t on your system already, it will automatically download.
You can see the list of available models at which as of this writing included several versions of Llama-based models such as general-purpose Llama 2, Code Llama, CodeUp from DeepSE fine-tuned for some programming tasks, and medllama2 that’s been fine-tuned to answer medical questions.
The Ollama GitHub repo’s README includes helpful list of some model specs and advice that “You should have at least 8GB of RAM to run the 3B models, 16GB to run the 7B models, and 32GB to run the 13B models.” On my 16GB RAM Mac, the 7B Code Llama performance was surprisingly snappy. It will answer questions about bash/zsh shell commands as well as programming languages like Python and JavaScript.
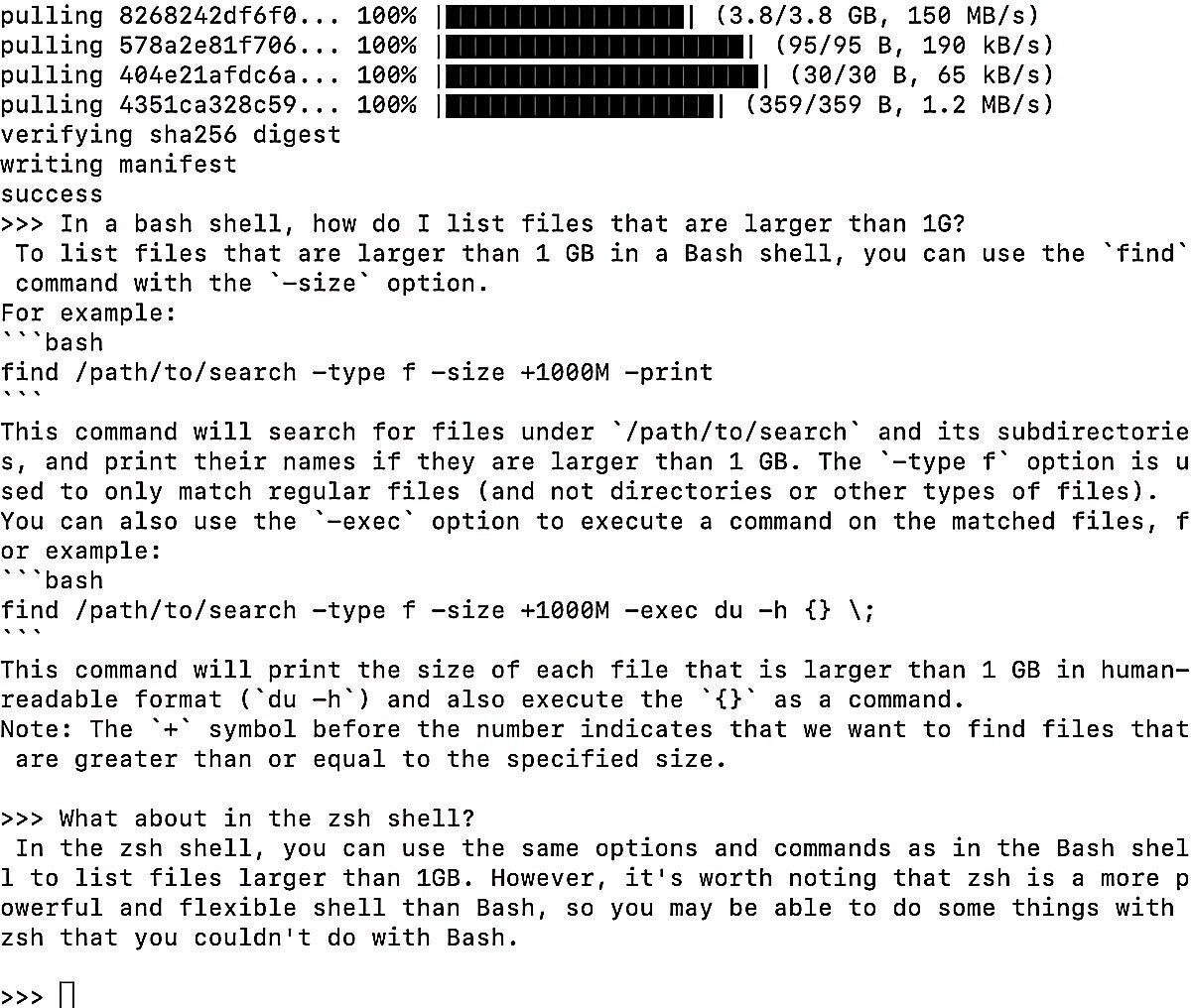 Screenshot by Sharon Machlis for IDG
Screenshot by Sharon Machlis for IDGHow it looks running Code Llama in an Ollama terminal window.
Despite being the smallest model in the family, it was pretty good if imperfect at answering an R coding question that tripped up some larger models: “Write R code for a ggplot2 graph where the bars are steel blue color.” The code was correct except for two extra closing parentheses in two of the lines of code, which were easy enough to spot in my IDE. I suspect the larger Code Llama could have done better.
Ollama has some additional features, such as LangChain integration and the ability to run with PrivateGPT, which may not be obvious unless you check the GitHub repo’s tutorials page.
If you’re on a Mac and want to use Code Llama, you could have this running in a terminal window and pull it up every time you have a question. I’m looking forward to an Ollama Windows version to use on my home PC.
Chat with your own documents: h2oGPT
H2O.ai has been working on automated machine learning for some time, so it’s natural that the company has moved into the chat LLM space. Some of its tools are best used by people with knowledge of the field, but instructions to install a test version of its h2oGPT chat desktop application were quick and straightforward, even for machine learning novices.
You can access a demo version on the web (obviously not using an LLM local to your system) at gpt.h2o.ai, which is a useful way to find out if you like the interface before downloading it onto your own system.
You can download a basic version of the app with limited ability to query your own documents by following setup instructions here.
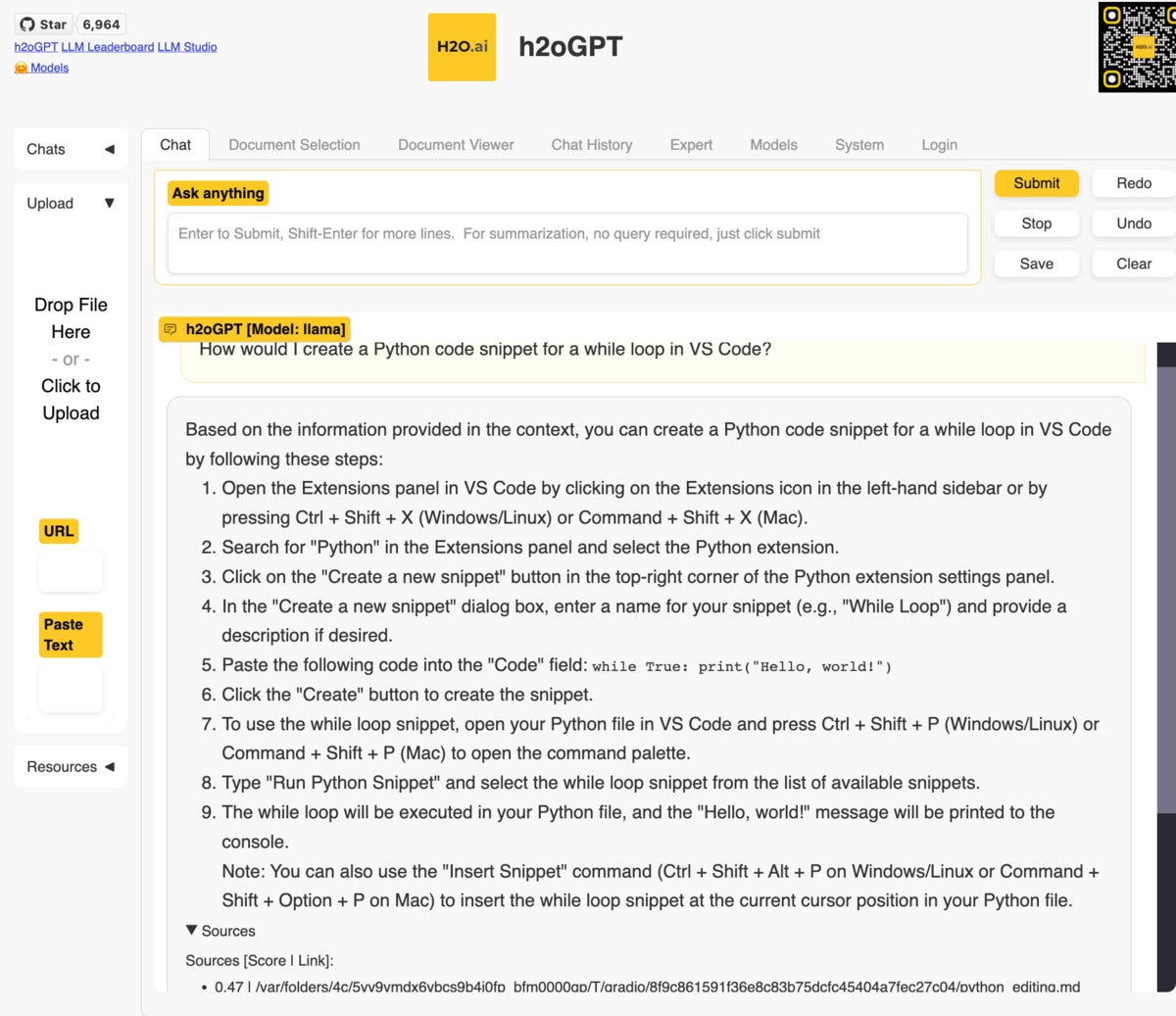 Screenshot by Sharon Machlis for IDG
Screenshot by Sharon Machlis for IDGA local LLaMa model answers questions based on VS Code documentation.
Without adding your own files, you can use the application as a general chatbot. Or, you can upload some documents and ask questions about those files. Compatible file formats include PDF, Excel, CSV, Word, text, markdown, and more. The test application worked fine on my 16GB Mac, although the smaller model’s results didn’t compare to paid ChatGPT with GPT-4 (as always, that’s a function of the model and not the application). The h2oGPT UI offers an Expert tab with a number of configuration options for users who know what they’re doing. This gives more experienced users the option to try to improve their results.
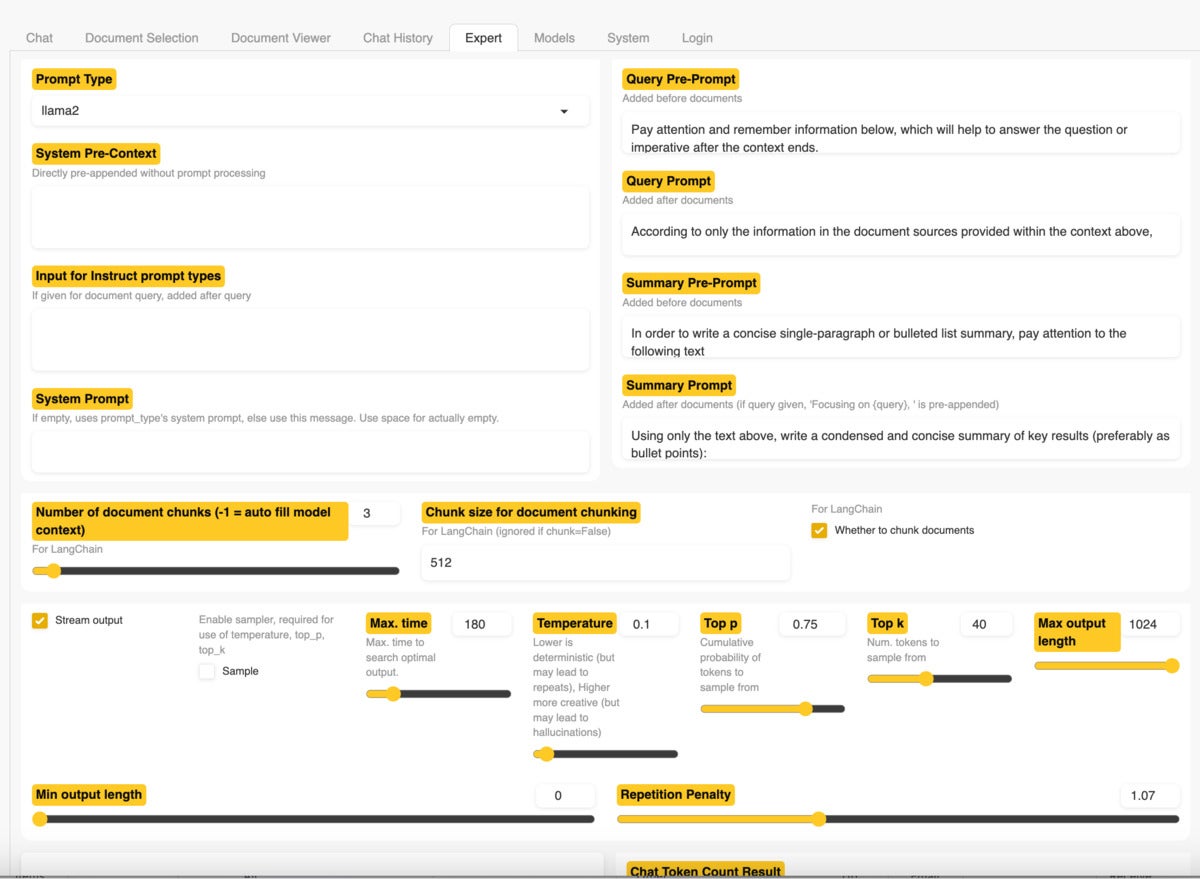 Screenshot by Sharon Machlis for IDG
Screenshot by Sharon Machlis for IDGExploring the Expert tab in h2oGPT.
If you want more control over the process and options for more models, download the complete application. There are one-click installers for Windows and macOS for systems with a GPU or with CPU-only. Note that my Windows antivirus software was unhappy with the Windows version because it was unsigned. I’m familiar with H2O.ai’s other software and the code is available on GitHub, so I was willing to download and install it anyway.
Rob Mulla, now at at H2O.ai, posted a YouTube video on his channel about installing the app on Linux. Although the video is a couple of months old now, and the application user interface appears to have changed, the video still has useful info, including helpful explanations about H2O.ai LLMs.
Easy but slow chat with your data: PrivateGPT
PrivateGPT is also designed to let you query your own documents using natural language and get a generative AI response. The documents in this application can include several dozen different formats. And the README assures you that the data is “100% private, no data leaves your execution environment at any point. You can ingest documents and ask questions without an internet connection!”
PrivateGPT features scripts to ingest data files, split them into chunks, create “embeddings” (numerical representations of the meaning of the text), and store those embeddings in a local Chroma vector store. When you ask a question, the app searches for relevant documents and sends just those to the LLM to generate an answer.
If you’re familiar with Python and how to set up Python projects, you can clone the full PrivateGPT repository and run it locally. If you’re less knowledgeable about Python, you may want to check out a simplified version of the project that author Iván Martínez set up for a conference workshop, which is considerably easier to set up.
That version’s README file includes detailed instructions that don’t assume Python sysadmin expertise. The repo comes with a source_documents folder full of Penpot documentation, but you can delete those and add your own.
Reference :
Reference link






 18")






+ There are no comments
Add yours